- Feb. 27, 2019
- --
DIY: How to build an AI-backed search result ranking system
-
 Christopher ZimmermannProduct Manager, Magnolia
Christopher ZimmermannProduct Manager, Magnolia


Content management systems hold vast amounts of diverse information. This ranges from technical configuration over web site text to visual media, all in one place. Navigating this maze of information can be a challenge, especially when done proactively. It takes a lot of effort to recall on which one of the hundreds of pages exactly that one sentence we're trying to change is buried. Or was it actually page, or maybe the caption of an image asset?
To make everyone's life a bit easier, we've come up with a simpler approach to navigation in a CMS: Live, type-ahead search. The Find Bar is a central part of the new interface in Magnolia 6. Its underlying engine called Periscope is aware of any piece of content or configuration that is searchable. Start typing a key word and it immediately begins listing matching items even from the remotest corners of your digital storehouse.
Idea
Having a central, omniscient search tool is just the start. The productivity gains it brings to users can be amplified even further by improving the way it ranks search results, pushing appropriate information ever closer to the user. This goal of continuous improvement of the search results is what motivated us to come up with a smart result ranking system for the Periscope.
Adaptive ranking
When dealing with large piles of content, not all of it is used at the same frequency. In fact, people are often searching for the same things over and over again. The most obvious way to determine what the top searched items are is by observing real users, ideally the ones we are trying to optimize for. Therefore it would be desirable to have the search tool learn from what results users pick and move them closer to them.
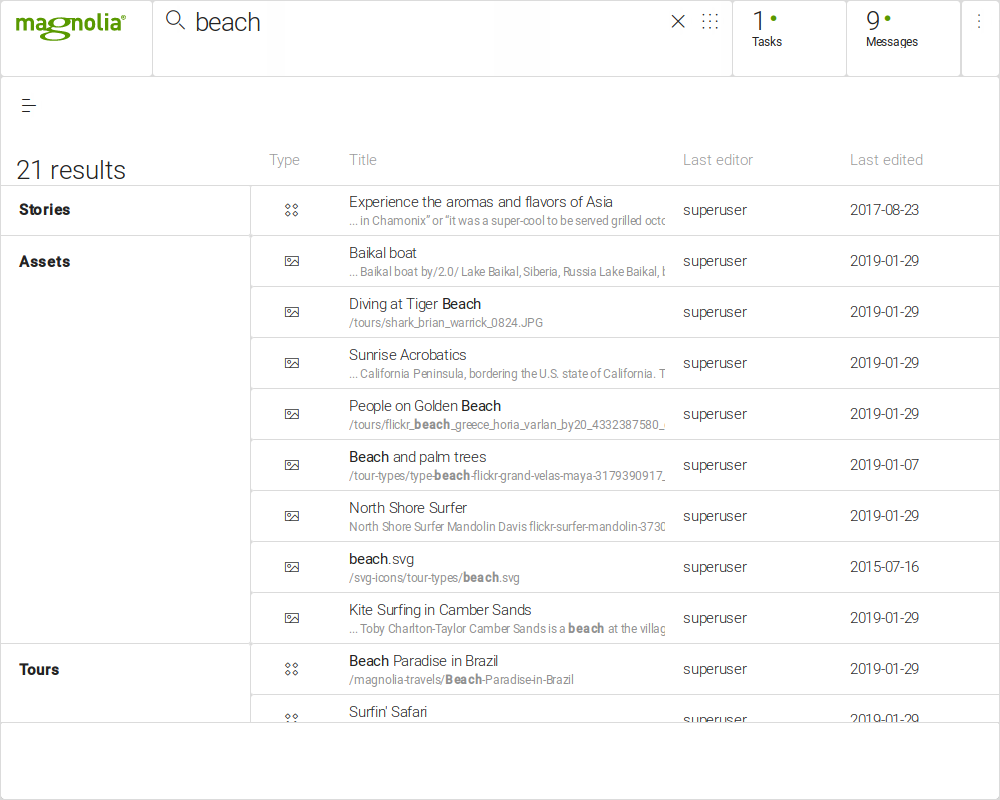
Rank based on word fragments
An obvious approach for adaptive result ranking would be to simply count how many times a user clicked which result and rank results based on click count. However, we wanted to go a step further, and have a ranking based on search queries and that remains stable for similar queries. While typing ahead, it should not make a big difference if the current word fragment has one character more or less. For example, if someone used to type out "cargo" in the past and often chose a particular result, like a page about "Cargo Pants", the system should be smart enough to also list that result high when only typing part of the search term, like "carg...".
Now imagine the scenario of a user starting to type a search query. While the search term is growing, the search engine should continuously list results on-the-fly and bubble those to the top that seem most relevant given the partial information at that point. For example, "c..." might suggest "Cooking", while typing ahead "car..." would list "Car Floor Mats" on top, and "carg..." finally "Cargo Pants".
User-specific ranking
Different users may have different preferences. We account for this fact by using multiple instances of our ranking system, each learning peculiarities of user groups or individuals. While not technically difficult to carry out, it played an important role in our decisions regarding hardware resource intensity as explained later in the post.
Implementation
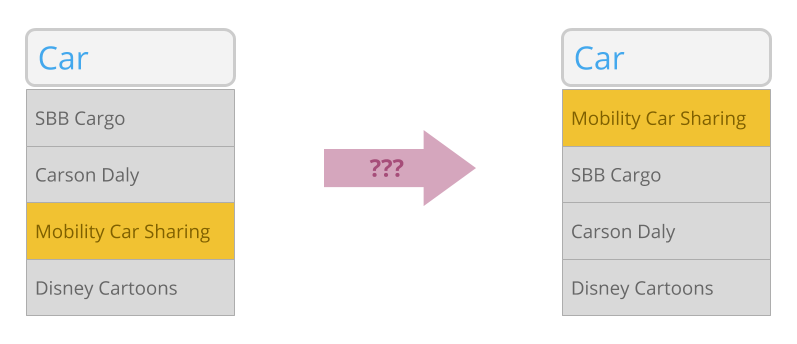
In order to represent the function mapping a search term to an appropriate result ranking, we make use of an artificial neural network. More precisely, our neural network maps a search query to a series of scores, whereas each score represents one of the results and higher scores represent higher relevance for this query.
The network's architecture has been crafted in a way to support the desired properties described above as good as possible. Let's break it down piece by piece.
Two-dimensional input layer
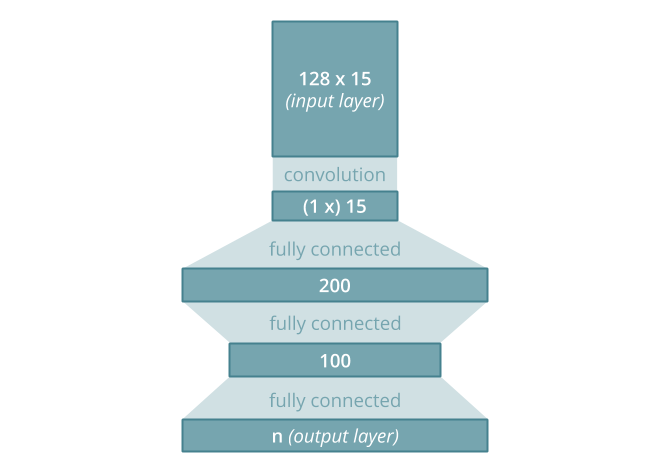
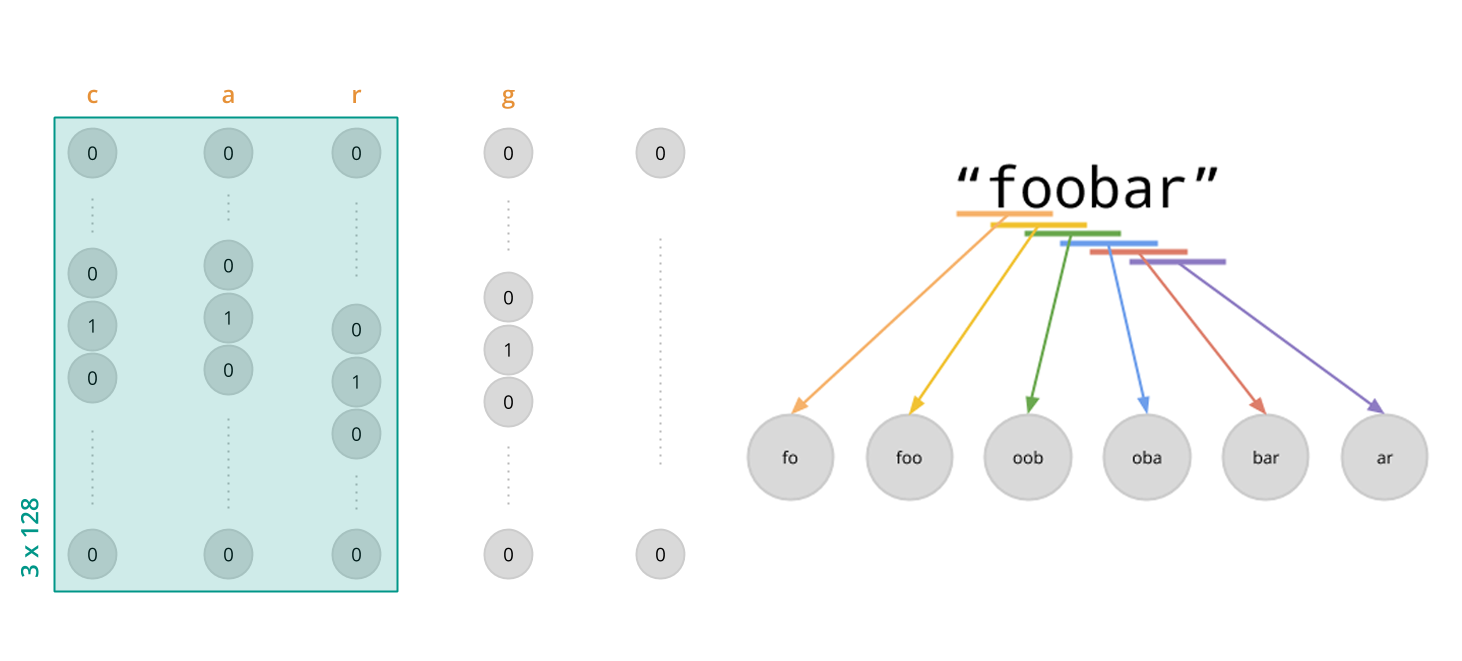
Our input layer has a two-dimensional shape, consisting of 15 × 128 units. Each column represents one character of the input, meaning we consider a maximum of 15 characters of the search term for ranking, following ones are cropped off. This is justified by the fact that typing out 15 characters should rarely be necessary in order to find a sought-after item. If it happens anyway, ranking does not completely break down but just operates on the first 15 characters.
Search terms are initially mapped to ASCII by either replacing characters with diacritics (like accents) by their plain counterparts, or, where that's not possible, by removing them completely. Each plain-ASCII character gets then mapped to an array of size 128 using a one-hot encoding. The resulting array consists mostly of zeros except for the index of the characters ASCII code, where a 1 is inserted.
Initial convolution
The first set of connections after the input layer forms a convolution with kernel size 3 × 128, folding three columns at a time to a unit in the second layer. Since every input layer column represents one character of the original input string, this convolution has the semantic effect of associating three neighboring characters with each other while also flatting our layers. Consequently, the second layer is one-dimensional and consists of 15 units.
Fully-connected hidden layers
At the core of our network, we've placed two layers of size 200 and 100, respectively, each fully connected to both sides. They are in place to give some "room" for approximating complex patterns in the relationship of search query on the input side and result relevance on the output side.
Choosing the number of size of those "brute-force" hidden layers is a trade-off between accuracy, computation cost and memory usage. In order to find the sweet spot, we outlined our desired behavior using unit tests first, then reduced the size as much as possible while making sure they would still hold. That means we have a couple of scenarios with example result list on which we simulate a user searching for specific terms and picking specific results, then assert that results later get re-shuffled in a desirable way.
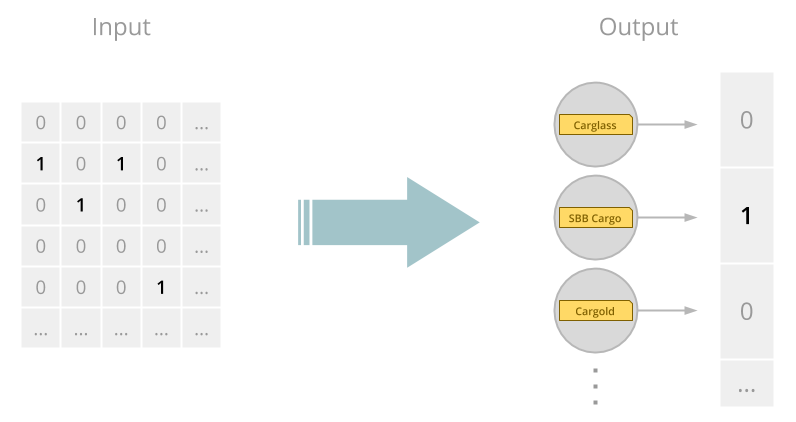
Output layer and mapping to results
Our output layer consists of n units, where n is the maximum number of results that can be memorized at a time by our ranking system. Each output unit potentially represents one item in the whole (known, memorized) result space, and its activation value represents relevance for ranking. During a search, a forward pass on the neural network maps a score to each result, letting us sort them by that score, or user relevance, semantically speaking.
Training
Training data is gained from users selecting a result after launching a search with a query string. After a user has clicked a result, the current search term is encoded for the input layer using above mapping to be later fed to the neural network for a fitting step. The corresponding output is a one-hot-encoded array of the selected result among all known ones. Intuitively speaking, we're exaggerating the relevance of one particular data tuple at a time, nudging it in the direction of knowing user preference a bit better. Over many such iterations initiated by user searches, the network eventually converges to a state of a middle ground between those hints, generating appropriately higher or lower relevance scores for particular results.
The size limit problem
The Periscope API is pluggable and result suppliers accordingly generic. Thus, the space of all potential results is de-facto unlimited, or at least open-ended. This is somewhat problematic since we're aiming for a one-on-one relationship between output layer units and results. Artificial neural networks are generally not very supportive to having their structure changed - at the very least, it's not common practice to change a model after having already run some training, since the effect on subsequent passes is hard to predict.
Another problem with an ever-growing pool of results is the demand for resources. Each output unit is connected to 100 units in the lowest hidden and therefore comes with 100 weights to be processed and kept in memory. Even with fairly moderate usage on an example Magnolia installation that's fairly thin on content, the number of totally seen results already easily grows into hundreds or thousands. Given that we use separate rankers for different users or groups, and that real-world setup may have more content by magnitudes, trying to keep everything memorized would eventually become a liability not only on CPU and main memory, but also on disk space occupied by backups.
In order to prevent those problems and keep resource consumption of ranking predictable, we've introduced a limit for the number of results being memorized. Whenever the limit is reached, an old result is forgotten in favor of the new one. However, this presents us with two new problems: First, it needs to be decided which result should be dropped, and second, the corresponding neural network output unit needs to be re-mapped to the newly added one and should forget any previously learned ranking.
For this, we utilize a special form of an least-recently-used (LRU) buffer that is able to keep track of indices and keeps the same index on an item for its whole life cycle within that buffer. At its core, it consists of a classic LRU map with results as keys pointing to neural network output layer indices as values. Whenever the user picks a result, it's bumped to be the new most-recently-used one in the buffer.
As an additional challenge, whenever a result entry in the circular buffer is replaced, the neural network should be cleared from any learned bias as well. We achieve this by resetting all input weights in front of the corresponding output layer unit. It should be noted that previous training with the now-defunct result most likely has had influence on weights in front of other hidden layers as well. But the last hidden layer can be interpreted as a feature representation of inputs that evolved over many trainings and may therefore be relevant and valid independent of the result currently represented in the output layer, so no harm is done there.
Learning rate
Among the hyper-parameters of our neural network, the learning rate stands out as quite different compared to other common deep learning scenarios. Our source of data for training is relatively sparse. One data point is generated whenever a user picks a result after searching. For the system to be useful, we'd want it to start having meaningful suggestions even already after a handful of searches, so we chose a particularly high learning rate of 0.01.
With scanty data in an online learning system like this, choosing the learning rate is a trade-off between having meaningful results as soon as possible and avoiding overshooting the goal due to overfitting, meaning already-learned information quickly gets overridden by new one, and generalization barely happens.
Persistence
A learning, personalized ranking system becomes increasingly useful over time as it obtains more and more data. Therefore it's important to persists its complete state across user session and application runs. Having a solid, clean persistence plan also makes it easy to transfer that state between different installations to make updates other chores more seamless.
The complete state of our ranking system includes two major parts: The neural network with it's model and trained parameters, and the results buffer annotating the network's output layer. Both of which are straightforward to be serialized, so we won't go into technical details about this.
However, the mere number of parameters on the neural network, mostly unit input weights, leads to significant resource consumption. Saving that network may take up to several seconds, depending on setup and hardware in place. Under heavy use, in particular when many users share the same ranking instance, the frequency at which searches are executed and training samples obtained can easily be higher than how fast the state can be stored. Trying to persist state after every training step would lead to such tasks queuing up unnecessarily.
In a long-running application like a CMS, there's no need to save state of our ranking immediately after any mutation. It's enough to have certainty that it will be eventually persisted within a reasonable time frame. To save some resources and avoid growing queues, we're limiting the frequency at which ranking state is stored. Requests for storing are recorded, but not immediately executed. Whenever a new request arrives, it overrides the previous one since that one would now be obsolete anyway. Once per a given time interval, like 30 seconds, the currently staged request gets finally executed.
Personal takeaways
When we started off with this project, it was our first real-world shot at deep learning techniques. Even though we're much rather application developers than academic-level experts on machine learning, we believe to have managed to come up with a sensible solution to an arguably complex problem. A lot of this is owed to the vast availability of learning resources provided by the machine learning community. There are several great books and uncountable online tutorials on that topic, often made freely available. Entry barriers to getting started on deep learning are lower than ever, and the possibilities are huge. We encourage anyone who's interested in the topic to just go for it and give it a try!

